
Открыт доступ
Компания Яндекс разработала и открыла для всех библиотеку под названием YaFSDP. Об этом в середине июня 2024 г. сообщило пресс-служба компании.
По словам создателей, она позволяет значительно ускорить обучение больших языковых моделей. Новая разработка ускоряет обучение нейросетей до 25% - результат зависит от архитектуры и параметров конкретной модели. YaFSDP также позволяет расходовать до 20% меньше ресурсов графических процессоров (GPU), необходимых для обучения. Благодаря этому YaFSDP задействует ровно столько графической памяти, сколько нужно для обучения, при этом коммуникацию между GPU ничто не замедляет.

Библиотека YaFSDP оптимизирует использование вычислительных мощностей процессоров на всех этапах обучения модели, ведь это особенно важно для стартапов или научных проектов в учебных заведениях. Библиотека также применима для нейросетей, генерирующих изображения.
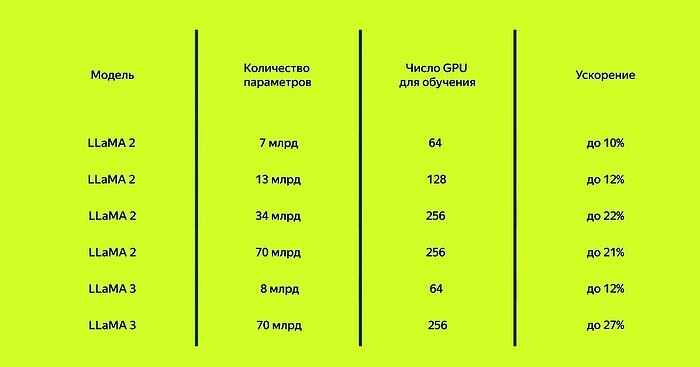
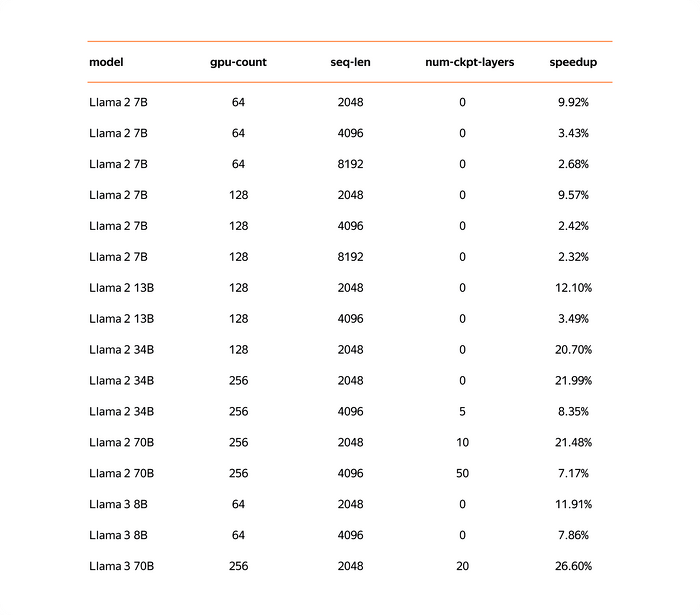
Компания Яндекс разработал YaFSDP для обучения своей генеративной модели нового поколения YandexGPT 3. Однако компания уже протестировала библиотеку на сторонних нейронных сетях с открытым исходным кодом и обнаружила, что библиотека YaFSDP позволяет значительно сократить время обучения. Например, если бы YaFSDP использовалась для модели LLaMA 2, то этап предварительного обучения сократился бы с 66 дней до 53.
Исходный код YaFSDP уже доступен на GitHub.
Экономия памяти
Искусственный интеллект (ИИ) - область, которой в последнее время уделяется большое внимание. Успех технологии обусловлен прогрессом в области глубокого обучения, объединяющий методы автоматического обучения основанные на нейронных сетях. Эти нейросети доказали свою эффективность при решении очень сложных задач в различных областях. Однако их эффективность в решении задач зависит от ряда факторов: архитектуры модели, ее размера, того, как и где проводилось их обучение. Большинство исследований показывают, что большие модели обеспечивают более высокую точность, но они и более дорогие.
Более крупные модели обеспечивают более высокую точность, но их обучение также обходится дороже. Основные проблемы связаны с вычислительной мощностью и ограниченной памяти машин, ведь если модель слишком велика, ее обучение может занять много времени (дни или даже месяцы). В процессе обучения необходимо хранить веса (параметры модели), активации (промежуточные расчетные данные) и состояния оптимизатора.
Обучение может быть распределено между несколькими ресурсами вычислительной платформы, и различные техники распараллеливания. Структуры данных, которые остаются неактивными в течение длительного периода времени, могут быть временно выгружены в более крупное пространство хранения с возможностью извлечения их позднее (стратегии выгрузки). Наконец, активации, которые вычисляются на каждой итерации, могут быть удалены и пересчитаны несколько раз в течение итерации (стратегии рематериализации). Стратегии экономии памяти обычно связаны с временными затратами по сравнению с прямым выполнением.
Веса, градиенты, состояния оптимизатора зависят от количества процессов, и потребляемая память стремится к нулю при увеличении количества процессов. Буферы занимают константную память. Активации зависят от размера модели и количества токенов на процесс.
Выходит, единственное, что занимает память, - это активации. Для Llama 2 70B с батчем в 8192 токенов и flash 2 на хранение активаций уйдет более 110 ГБ. Можно существенно уменьшить нагрузку на память, если использовать чекпоинт активаций: на forward разработчики сохраняют только активации между трансформерными блоками, а на backward заново перевычисляют их, а это сильно экономит память. Для хранения активаций потребуется всего 5 ГБ, но избыточные вычисления будут занимать 25% времени для всего обучения.
Поэтому имеет смысл освобождать память для того, чтобы не делать чекпоинт активаций для как можно большего числа слоев. Кроме того, есть способы уменьшить и объем коммуникаций в случае, если есть лишняя свободная память.
Итоговое ускорение в сценариях с небольшим батчем превышает 20%, что делает YaFSDP удобным инструментом для дополнительного обучения ИИ-моделей. В претрейнах компании Яндекс внедрение YaFSDP вместе с другими оптимизациями памяти в итоге дало ускорение в 45%. Теперь инструмент можете использовать любой разработчик. В Яндекс готовы рассмотреть возможные пул?реквесты от пользователей.
 Поделиться
Поделиться